What is LLaMA?
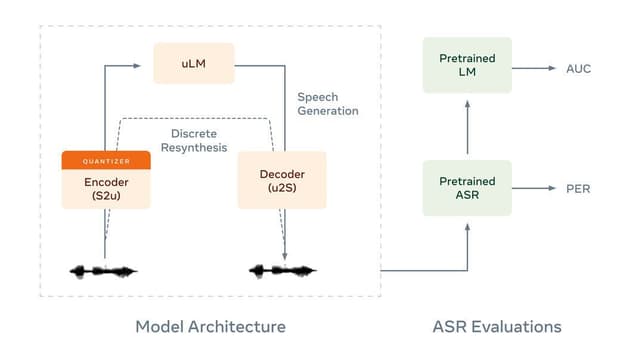
Textless NLP revolutionizes natural language processing by utilizing raw audio recordings to generate expressive speech in multiple languages and accents. With its advanced algorithms, this innovative technology captures subtle nuances like tone, intonation, pitch, and pauses, resulting in more natural and engaging conversations between users and their applications. It caters to various use cases, including voice-driven digital assistants, bots, and automated customer service systems. The versatility of Textless NLP allows it to be seamlessly integrated into mobile and web applications as well as devices, ensuring a user-friendly experience. Moreover, it prioritizes user data security with built-in protective measures. Overall, Textless NLP empowers users to create compelling and interactive interactions with their applications.
Information
- Price
- Contact for Pricing
Freework.ai Spotlight
Display Your Achievement: Get Our Custom-Made Badge to Highlight Your Success on Your Website and Attract More Visitors to Your Solution.
Website traffic
- Monthly visits106.08K
- Avg visit duration00:00:12
- Bounce rate63.15%
- Unique users--
- Total pages views216.84K
Access Top 5 countries
Traffic source
LLaMA FQA
- What is the purpose of LLaMA?

- How can LLaMA be used?
- What are the sizes of LLaMA?
- What languages were used to train LLaMA?
- How can researchers access LLaMA?
LLaMA Use Cases
LLaMA is a large language model designed to help researchers in the field of AI advance their work.
LLaMA is a foundational model that can be fine-tuned for various tasks and use cases.
Training smaller foundation models like LLaMA requires less computing power and resources compared to larger models.
LLaMA is available in different sizes, ranging from 7B to 65B parameters.
LLaMA can generate creative text, solve mathematical theorems, predict protein structures, and answer reading comprehension questions.
LLaMA is designed to be versatile and can be applied to many different use cases.
LLaMA can help researchers understand and address issues such as bias, toxicity, and misinformation in large language models.
LLaMA is released under a noncommercial license focused on research use cases.
Access to LLaMA is granted on a case-by-case basis to academic researchers, government organizations, civil society, and industry research laboratories.
The AI community must work together to develop clear guidelines for responsible large language models.